snowflake是什么
snowflake单词原意为雪花,是twitter开源的一种分布式ID生成算法。该算法可以保证在不借助第三方服务或者说工具的情况下,在多台机器上持续生成保证唯一性的64位整型ID。
snowflake ID的组成
snowflake将ID的64位划分为四块区域,分别填入的是当前服务实例的数据中心ID,节点ID,时间戳,以及相同时间戳下的递增序号。
以下是snowflake原始算法中,各字段的顺序以及所占的位数:
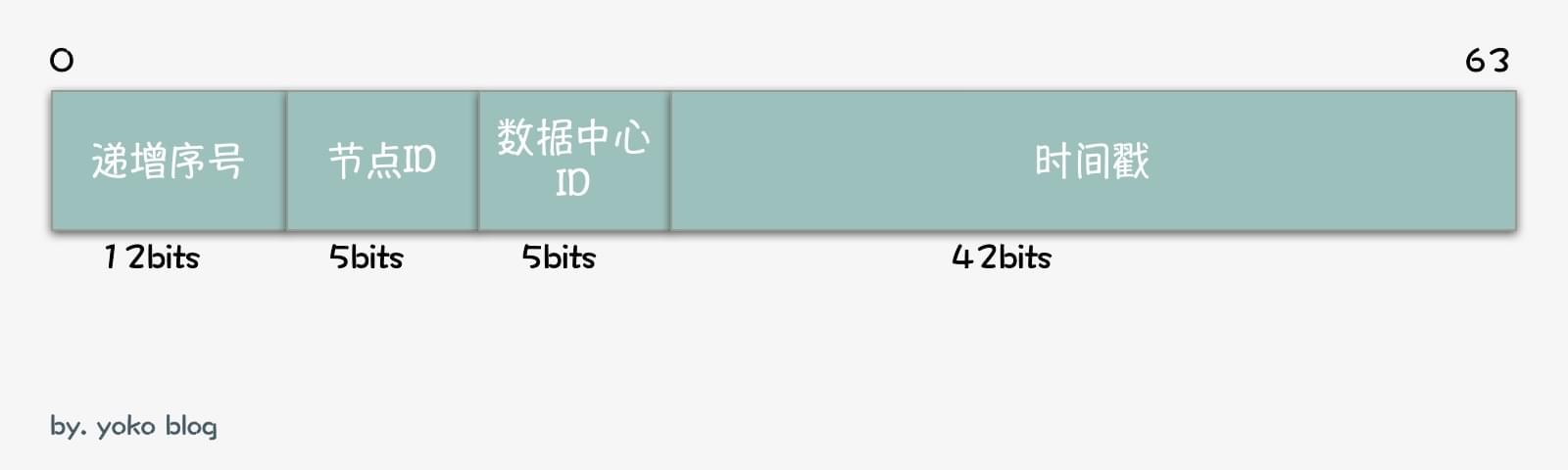
小提示,在生产环境,使用snowflake的思想生成分布式ID时,这些字段所占的位数可以根据自身业务灵活调整。本文如无特殊说明,都是针对snowflake原始算法进行讲解。
数据中心ID和节点ID
不同的服务实例间,使用不同的数据中心ID和节点ID,可以保证生成的ID不重复。
从该算法使用数据中心ID加节点ID(而不是单个服务实例ID)的方式决定服务实例的唯一性,也可以看出,该算法设计之初是一个非常面向具体业务场景的算法。
数据中心ID和节点ID分别占5位。即整个系统最多可以有32个数据中心,每个数据中心最多可以有32个节点。为什么数据中心ID和节点ID是5位?额,应该也是twitter根据当时的业务拍脑袋拍的。
那么数据中心ID和节点ID怎么生成呢?这点不由snowflake负责,也即这两个ID在多个服务实例之间不重复是由snowflake的调用方保证的。比如一种简单的方式是直接使用静态配置,这种方式适用于节点数量比较少且相对固定的情况下。
时间戳
如前文图中展示,snowflake使用42位存储时间戳。
我们平时所说的UNIX时间戳,指的是从1970年1月1号0点到现在所经过的时间。如果单位是毫秒,需要使用64位整型存储。
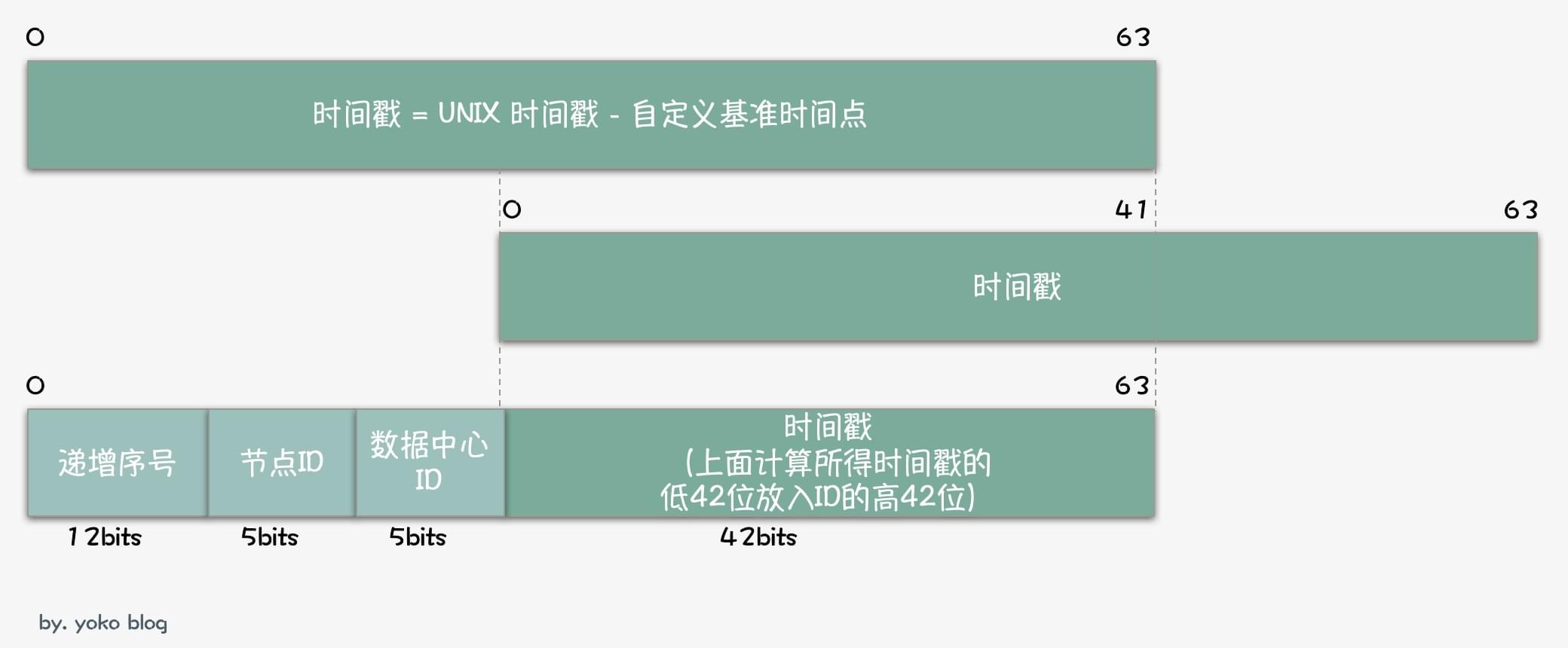
由于在snowflake算法中,只需要保证时间戳随时间递增即可,所以snowflake中的时间戳是使用UNIX时间戳减去一个基准时间,这个基准时间在原版代码中是1288834974657,也即2010/11/4 9:42:54.657。你也可以换种方式理解,即从2010年11月4号xxx这个基准时间点到现在所经过的时间。
减去自定义的基准时间后,时间戳比UNIX时间戳小了很多,snowflake使用得到的时间戳的低42位作为ID的一部分(即ID的高42位)。如下图所示:
时间戳可能存在的问题
首先,时间戳随着系统时间增长,当时间戳的第42位增长到1时,ID的最高位也将变为1。由于snowflake默认使用有符号64位整型,最高位为符号位,这将导致生成的ID变为负数。
通过如下公式(1<<41) / 1000 / 60 / 60 / 24 / 365计算,可知道在基准时间上(snowflake默认的基准时间是2010/11/4)再过69.7年,将出现ID为负数的情况。
这里展开说明下,如果想要生成的ID永远不为负数,可以保持ID的最高位始终为0,其他的字段减少1位,比如说时间戳只使用41位。这样时间戳出现翻转归零的时长缩短1倍,大概为35年,基本上是可接受的。你可能会说,69.7年已经足够长啦,到出现负数的时候我早退休了,哪管它洪水滔天。但是假设你要设计一个32位的分布式ID生成器呢?此时你必然需要考虑哪些字段可以缩短,时间戳多久出现翻转(也即ID可能翻转)不影响业务。
第二,假如单台机器上,获取当前时间的方法出现时间回退,那么可能出现ID重复的情况。
第三,假如服务重启,重启后时间戳没变(即1毫秒内重启成功),那么此时snowflake丢失了重启前当前时间戳的递增序号,递增序号重新从0开始,也可能出现和重启前生成的ID重复的情况。
最后一点值得注意的是,一个服务上线后,基准时间点不应该随意修改。避免造成时间戳回退。
递增序号
如前文图中展示,snowflake使用12位存储递增序号。
为什么在时间戳的基础之上,还需要递增序号?因为即使是在单个服务实例中,我们也可能需要在1毫秒内生成多个ID,这种情况下,同1毫秒下的seq会从0开始顺序递增。12位的seq范围为[0, 4095],如果1毫秒内生成的ID数量超过4096怎么办呢,snowflake会阻塞直到时间戳更新后,再生成可用的ID返回给调用方。相关代码如下:
1 | now = time.Now().UnixNano() / 1e6 |
完整代码见:https://github.com/q191201771/naza/blob/master/pkg/snowflake/snowflake.go
snowflake 1毫秒可产生多少ID?
32(5位数据中心ID) * 32(5位节点ID) * 4096(递增序号) = 4194304
所生成ID的特点
单个服务实例生成的ID是递增的;多个服务实例生成的ID,受限于系统时间不一致,或者是节点ID的大小,可能出现整体ID不递增的情况。
总结
好了,至此,snowflake算法就基本介绍完毕了。算法的实现部分十分简单,不到100行代码,基本上就是一些位操作。
感兴趣的可以看看我写的一份Go语言实现:snowflake.go,在twitter原始scala实现版本的基础上,额外支持配置所有的字段所占的位数(比如支持将数据中心ID所占位数设置为0,从而只使用节点ID),支持配置基准时间,支持配置是否永远不返回负数ID,支持并发调用。
twitter放在github上的原始版本,master分支的代码已经删了,只能在release下载老版本的源码压缩包。
最后,感谢阅读,如果觉得文章还不错,可以给我的github项目naza来个star哈。该项目是我学习Go时写的一些轮子代码集合,后续我还会写一些文章逐个介绍里面的轮子以及一些写Go代码的技巧。
naza项目地址: https://github.com/q191201771/naza
naza的其他的文章:
本文完,作者yoko,尊重劳动人民成果,转载请注明原文出处: https://pengrl.com/p/20041/