本文介绍如何用c语言实现一个简单的内存分配器,可替换glibc中的 malloc(), calloc(), realloc(), free().
这是一篇入门级别的文章,所以不会介绍所有的细节。
代码实现主要为了演示内存分配器的基本工作原理,所以和工业级内存分配器相比,缺少非常多的性能优化,分配内存时也不会按页对齐,但是至少,我们构建的内存分配器是可以工作的。
在构建内存分配器之前,需要先介绍程序的内存布局。操作系统中的进程运行在它自己独有的虚拟地址空间,不同进程间的虚拟地址空间是独立、相互隔离的。虚拟地址空间一般由以下5部分组成:
代码段(Text section):包含被处理器执行的二进制指令
数据段(Data section):包含程序中已手动初始化的全局静态变量和局部静态变量
BSS(Block Started by Symbol)段:包含了程序中未手动初始化的全局变量和局部静态变量。这部分数据会被初始化为零值。
堆:包含动态申请的内存
栈:包含了局部变量,函数参数等
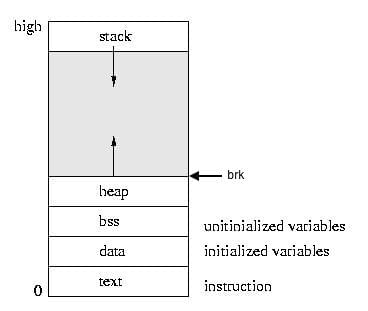
如上图所示,栈和堆的增长方向是相反的。
有时数据段、BSS段、堆三个区域会统称为”数据段”(data segment),
它的尾部被一个叫做brk(program break)的指针所指向。
也就是说,brk指向堆的尾部。
如果我们想在堆上申请更多的内存,我们需要向操作系统请求增长brk。同理,释放内存时需要向操作系统请求减小brk。
在Linux系统(或其他Unix-like系统)下,我们需要使用sbrk()系统调用来操作程序的brk指针。
调用sbrk(0)返回当前brk的位置。
调用sbrk(x)并传入正数表示对brk增长x字节大小,即分配内存。
调用sbrk(-x)并传入负数表示对brk减少x字节大小,即释放内存。
如果函数调用失败,sbrk()将返回(void*)-1。
除了sbrk(),还可以使用mmap()申请内存。sbrk()并不是真正的线程安全。并且它只能按后进先出的顺序增长和收缩。
如果你执行man 2 sbrk命令查看帮助手册,它会告诉你:
1 | brk和sbrk是早期虚拟内存管理出现之前的历史遗留产物。 |
然而,glibc中的malloc依然使用sbrk()来申请小块内存,具体可以见The GNU C Library: Malloc Tunable Parameters。
所以,我们也使用sbrk()来实现我们的简单版本内存分配器。
malloc()
malloc(size)函数申请size字节大小的内存并返回指向所申请内存的指针。
第一版代码实现如下:
1 | void *malloc(size_t size) |
上面的代码,我们指定size调用sbrk()。
如果成功,size大小的内存在堆上被申请。
这很简单,然而真是这样吗?
问题在于我们如何释放这块内存。
free(ptr)函数释放ptr指针指向的内存块时,ptr指针必须是之前通过malloc()或calloc()或realloc()调用返回的指针。
但是释放一块内存的首先前提是,我们知道这块内存的大小。在上面这个实现中,我们没有地方获取关于大小的信息。所以,我们需要某种方法将大小信息存放在某处。
此外,我们需要理解,操作系统所提供的堆内存是连续的。所以我们只能释放堆尾部的内存。我们不能将堆中间的内存释放给操作系统。你可以把堆想象成一个长条面包,你只能在尾部对它进行伸长或缩短,但是你必须保证它的完整性。
为了解决堆里面非尾部内存无法释放的问题,从现在开始我们将区分两个概念:freeing内存和releasing内存。
freeing一块内存并不强制要求将这块内存归还给操作系统。这意味着我们只是把这块内存标记为free(空闲)。这块被标记为空闲的内存可以在稍后被重复使用(比如调用malloc)。由于非堆尾部内存无法释放,这是我们目前唯一的释放方法。
releaseing一块内存则是将这块内存归还给操作系统。
现在,每块被申请的内存块有两个信息需要存储:
- 大小
- 内存块是否空闲,可在稍后被重复使用
为了存储这些信息,我们为每个新的被申请的内存块添加一个自定义header。
header看起来像这样:
1 | struct header_t { |
我们的设计很简单。当程序申请size字节大小的内存,我们计算total_size = header_size + size,并调用sbrk(total_size)。再在通过sbrk()申请得到的内存空间中放入header和真正的内存块。header被内部管理,它对上层应用是完全不可见的。
现在,我们的每块内存块看起来像这样:
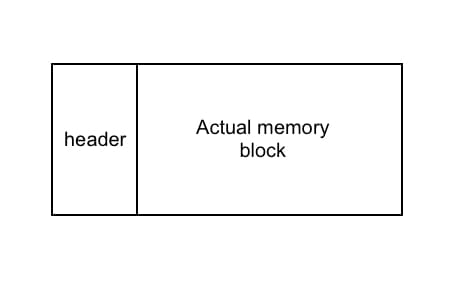
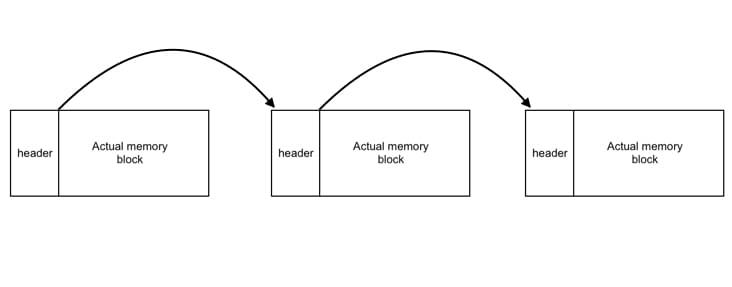
我们不能百分百肯定通过我们malloc申请的内存块是连续的。因为上层应用可以不通过我们的malloc调用sbrk()。我们需要有一种手段遍历我们的所有内存块(为什么需要遍历?在后文中谈free()的实现时会解释)。所以为了记住所有通过我们malloc申请的内存块,我们会将这些内存块放入一个链表中。现在我们的自定义header格式如下:
1 | struct header_t { |
内存块链表看起来像这样:
现在,我们把整个自定义header结构体和一个16字节大小的占位变量封装入一个联合体中。这使得自定义header在内存中占用16个字节大小。因为联合体的大小取决于其中最大元素的大小。自定义header之后紧跟着的就是实际提供给上层应用使用的内存块。
1 | typedef char ALIGN[16]; |
我们会有头尾两个指针用于记录整个链表。
1 | header_t *head, *tail; |
为了防止多个线程并行访问内存,我们引入了基础锁机制——互斥量。
我们使用一个全局锁,所有对内存的操作都需要获取这个锁,完成操作后释放这个锁。
1 | pthread_mutex_t global_malloc_lock; |
我们的malloc现在修改成了这样:
1 | void *malloc(size_t size) |
让我来对上面这段代码做个解释:
首先检查申请的大小是否为0。如果是0,则返回NULL。
对于有效的大小,首先获取锁。然后调用get_free_block() - 这个函数会遍历链表,检查是否存在已被标记为空闲并且大于申请大小的内存块。这里,我们按链表的顺序查找并进行选取。
如果存在一个大于申请大小的空闲内存块,我们将这块内存标记为非空闲,释放全局锁,并返回一个指向该内存块的指针。这种情况,header指针指向刚才遍历链表所找到的内存块。注意,对于上层应用,我们需要隐藏header的存在。当我们执行(header + 1),指针指向header之后的位置。也即是真正内存块的起始位置,上层应用感兴趣的位置。然后将指针类型转换成(void*)并返回。
如果没有找到足够大的空闲内存块,我们将调用sbrk()扩展堆。堆扩展的大小为申请大小加header的大小。因此,我们首先计算整体大小:total_size = sizeof(header_t) + size;然后,我们向操作系统申请增加brk:sbrk(total_size)。
在刚才向操作系统申请得到的内存块上,我们首先写入header。在c语言中,void*向其它指针类型转换时不需要强转类型。所以我们不需要显式的写成:header = (header_t *)block;
我们在header中填入上层应用申请的大小(而不是总大小),并且标记它为非空闲。我们更新header中的next指针指向,以及全局head和tail的指向,以保证链表为最新状态。正如前面所描述的,我们对上层应用隐藏header,所以返回(void*)(header + 1)。最后,确保释放全局锁。
free()
现在,我们来看下free()函数需要做什么。首先,检查被释放的内存是否在堆尾部。如果是,我们将这块内存归还给操作系统。如果不是,我们将它标记为空闲,期望稍后可以重用它。
1 | void free(void *block) |
首先,我们需要得到这块内存的header信息。即得到对应header的地址。做法很简单,我们只需要对free传入地址再向前移动header大小即可。header = (header_t*)block - 1;
sbrk(0)返回当前brk的位置。为了检查被释放的内存块是否在堆尾部,我们首先找到被释放的内存块的尾部,使用如下方式计算 (char*)block + header->s.size。然后用它和brk位置比较。
如果确实是堆尾部,那么我们可以收缩堆的大小并将内存归还给操作系统。首先,我们调整head和tail指针指向。然后,计算需要释放的内存大小。即header的大小和实际块的大小:sizeof(header_t) + header->s.size。为了释放这块内存,我们调用sbrk()并传入这个值的负数形式。
如果这块内存不是链表的最后一个元素,我们将header中的is_free字段设置为1。函数get_free_block()会检查这个字段以决定是否需要真正调用sbrk()。
译者yoko注,个人觉得在这个简单的内存分配器实现中,判断被释放的内存是否是堆尾部,可以直接判断该内存块是否为链表的最后一个元素。毕竟使用
sbrk(0)的方式多了一次系统调用。
补充说明,链表的最后一个元素为堆尾部成立的前提是,程序中所有的动态内存都是由我们自己的内存分配器所分配管理。用sbrk(0)则没有这个限制。
calloc()
calloc(num, nsize)函数申请一个数组的内存,数组元素个数为num,每个元素的大小为nsize字节,该函数返回指向被申请内存的指针。并且,这块内存内部的值都被初始化为0。
1 | void *calloc(size_t num, size_t nsize) |
这里,我们做了个快速的乘法结果溢出的检查,然后调用malloc(),并且通过memset()函数将申请的内存内部的值都初始化为0。
realloc()
realloc()函数用于修改内存块的大小。
1 | void *realloc(void *block, size_t size) |
这里,我们首先获取内存块的header,检查当前的大小是否已满足被要求的大小。如果已满足,则什么也不需要做。
如果大小不满足,我们调用malloc()来获取一块被要求大小的内存块,然后使用memcpy()将老内存块的内容拷贝至新的内存块上。然后对老内存块调用free()进行释放。
编译以及使用我们的内存分配器
完整代码见这个github仓库
我们会先编译我们的内存分配器,然后运行一个使用我们内存分配器的程序,比如说ls命令。
首先,我们把它编译成一个动态库文件。
1 | gcc -o memalloc.so -fPIC -shared memalloc.c |
-fPIC和-shared选项用于确保编译输出的文件的是代码位置独立的并且是可被动态链接的动态库。
在Linux,如果你将一个动态库文件的路径设置在环境变量LD_PRELOAD中,这个库文件会优先被加载。利用这个特性可以保证我们一会在shell中运行程序时使用我们实现的malloc(),free(),calloc()和realloc()。
1 | export LD_PRELOAD=$PWD/memalloc.so |
然后
1 | ls |
这就是使用我们内存分配器的ls运行的结果。
如果你不相信这一点,你可以在malloc()打印一些调试信息。
感谢阅读。欢迎评论。
英文原文地址: Memory Allocators 101 - Write a simple memory allocator by Arjun Sreedharan
本文完,作者yoko,尊重劳动人民成果,转载请注明原文出处: https://pengrl.com/p/18873/